One of the features my blog have been missing since I switched to Astro from WordPress have been a search function. I have looked around for something plug-an play but haven’t found anything that I really liked.
The easy solution would be to just find a fuzzy search library, e.g. https://www.fusejs.io/, and call it a day by following a guide like Daniel Diaz’s https://danidiaztech.com/create-astro-search-component/ - but what is the fun in that?
Instead I decided to build my own semantic search functionality, using text embeddings and Cloudflare’s new AI offerings. The benefit of semantic search over fuzzy search is that semantic search leverages LLMs to generate vector embeddings that encapsulates language understanding so we are not just searching for words that appear directly in my blog posts. A simple example of that is if you search for “hyper-v” my search now also returns blog posts about Virtual Box, because somehow the LLMs have understod that those two things are related.
In order to build semantic seach solution we need to go through a few steps:
- Select an embedding model
- Embed all content on the blog with the model
- Store the embeddings in a vector database
- Build a query API
- Build the search functionality into the blog
Select an embedding model
Everyone and their mum is building AI solutions now, so it leaves us with a lot of models to pick from. One of the requirement for my blog, is that it must be cheap to run, so I’m not very interested in embedding models that cost money to use, this leaves OpenAI and their ada and text-embedding-3-large models out of the questions. Instead I turned to open-source models and ideally I wanted to find a model that I could run locally on my MacBook, so it would be free for me to toy around with it. Since I’m not spending all my time to keep up with AI models, I tried to find something that worked without going into a rapid hole of evaluating different models against each other and spending days on that.
One of the models I saw referenced in different blog posts where the bge-base-en-v1.5 model (https://huggingface.co/BAAI/bge-base-en-v1.5). I also saw that this is one of the models that Cloudflare offers in their AI workers (https://developers.cloudflare.com/workers-ai/models/bge-base-en-v1.5/), which led me to the conclusion that it would be a good pick, as it would make it really easy for me to build the API in step 4). The output of the model when feed an input text is a vector of 768 float points. Some of the other models use longer vectors, which I assume would teoretically allow them to be better as they can embed more information, but since my data dataset only consist of a few hundred blog posts, I’m not too concerned, and smaller vectors should also make the model faster.
Embed all content on the blog with the model
The next step of the journey is to generate the vector embeddings of the content. If you are not using an open source model that can run locally your only choice here is to send the data to an API and pay for the embeddings to be generated. This is what e.g. Cloudflare Vectorize endpoint (https://developers.cloudflare.com/vectorize/get-started/embeddings/), Azure AI Search and many other SaaS products can do for you. But since I selected an open source model, I want to create the embeddings locally, which will cost me nothing.
As my goal here is to make a search function for my blog, and not spending my time on getting the model to run locally, I needed to find a tool that could help me with that.
One great tool that I have found for working with LLMs locally is Simon Willison’s LLM CLI https://llm.datasette.io/en/stable/, it provides a lot of handy LLM tools, and have a nice plugin architecture where he regularly publishes new plugins.
The plugin I used, is his wrapper (https://github.com/simonw/llm-sentence-transformers) around the python library sentence-transformers (https://www.sbert.net/). The cool thing about leveraging this python library is that it allows us to use different embedding models without having to do any work ourselves, and yes it has support for the bge-base-en-v1.5 model.
So basically to get a local sqlite database with embeddings for all my blog posts all I have to do is to run the following commands (you must have the LLM cli installed before hand):
## Install the plugin
llm install llm-sentence-transformers
## Install the model (it will download on first use)
llm sentence-transformers register BAAI/bge-base-en-v1.5
## Generate embeddings using the model to a table named posts from the path specific of the file type *.md and store the embeddings in a sqlite database named blog.db
llm embed-multi posts --model sentence-transformers/BAAI/bge-base-en-v1.5 --files ~/projects/sjkp-astro-website/src/content '**/*.md' -d blog.dbAfter 30 sec or so I now have a database around 800 KB with embeddings for all my blog posts.
Store the embeddings in a vector database
Now I have all my vectors in a SQlite database, but unfortunately for us to be able to search the through vectors we need something that is better suited for that than SQlite.
The concept that we are going for is when we type a search query, we need to generate the embedding vector for that text input, and then we need to see how similar that vector is to each vector in our database. The more similar the better the match.
One commonly used algoritm for determining similarity of vectors are cosine similiarty. So a great vector database would allow us to run this algoritm directly in the database. SQlite however cannot do that out of the box, there are some plugins that should make it possible, but I haven’t played with those yet.
To test locally we can use LLM CLI (it calculates the cosine similarity in python by pulling out all the vectors from the database, so not super fast, but for 200 vectors it is okay).
The command
## Looking for vectors in the posts table from the blog.db database, that are similar to the hyper-v vector
llm similar posts -c 'hyper-v' -d blog.dbThe result
{"id": "posts/move-docker-for-windows-hyper-v-disk-vhdx-to-another-drive/index.md", "score": 0.6889425812580343, "content": null, "metadata": null}
{"id": "posts/copy-of-virtual-machines-and-tfs-workspace-issues/index.md", "score": 0.6869361260977719, "content": null, "metadata": null}
{"id": "posts/increase-size-of-virtual-box-vhdvdi-image/index.md", "score": 0.6713834462378181, "content": null, "metadata": null}
{"id": "posts/running-macos-using-virtual-box-in-azure/index.md", "score": 0.664545521760157, "content": null, "metadata": null}
{"id": "posts/windows-server-2012-r2-on-virtualbox/index.md", "score": 0.6346273564839868, "content": null, "metadata": null}
{"id": "posts/running-pytorch-with-gpu-support-in-a-container-on-azure-vm/index.md", "score": 0.6285662347271673, "content": null, "metadata": null}
{"id": "posts/windows-azure-virtual-machines-and-sharepoint-2013/index.md", "score": 0.6157894588093106, "content": null, "metadata": null}
{"id": "posts/windows-2012-server-and-virtual-box-ie-crash/index.md", "score": 0.6152178812792359, "content": null, "metadata": null}
{"id": "posts/azure-bootcamp-2015-twitter-event-hub-stream-analytics-and-data-factory/index.md", "score": 0.6019545122828851, "content": null, "metadata": null}
{"id": "posts/semantic-search-for-astro-with-cloudflare-ai/index.md", "score": 0.6003042441084121, "content": null, "metadata": null}The score value is the actual output from the cosine similarity algorithm, the close to 1 the more similar the vectors are.
The vector database I decided to use is the one provided by Cloudflare in their Vectorize service. This is most likely not going to be my final solution, as I want something that is free and Vectorize is currently only accessible when on a paid workers plan (starting at 5 USD/month).
To create a new Vectorize database use the following wrangler cli command
wrangler vectorize create sjkpdk --dimensions=768 --metric=cosineYou define the name of the database/index and how many dimensions (length of the embedding vector) and you select your search algorithm, where cosine means cosine similarity.
Once the index is created it needs to be populated. That can be done from a cloudflare worker or using the REST API.
My worker code has a simple /insertraw endpoint that accepts json and post it directly to the vectorize index. In order to extract the vectors from the SQlite database I have written a little nodejs program, that submits the data.
You can find it here: https://github.com/sjkp/embedding-nodejs
Build a query API
Now that we have a populated vector database we are ready to build a query API.
I leverage the Cloudflare worker to do that. It boils down to a few lines of code, because the worker have direct access to the embedding model, and the vectorize database can do the cosine similary search for us. Quite nice.
let userQuery = new URL(request.url).searchParams.get('q') || '';
if (!userQuery) {
return new Response('Please provide a query parameter q', { status: 400 });
let start = performance.now();
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let mid = performance.now();
let matches = await env.VECTORIZE_INDEX.query(queryVector.data[0], { topK: 5 });
let end = performance.now();
return Response.json({
embedDuration: mid - start,
queryDuration: end - mid,
q: userQuery,
matches: matches,
});Performance of the API is decent, at worst a couple of seconds to embed and query across my 200 posts. At some point later I might want to build a non-cloudflare version of this API to see how much I could improve the performance. But the ease of use is hard to beat with Cloudflare.
The source code for the worker is upload to GitHub here: https://github.com/sjkp/cf-semantic-search
Build the search functionality into the blog
The last step of the journey is to write a little bit of JavaScript in my blog to call the query API.
Because the vector database only contains the vectors and an ID per post (the ID could only be 64 characters long, so I had to truncate some of them), I have to ‘join’ the IDs from the search result back to the metadata for the blog posts, so I can present a nice list of search results.
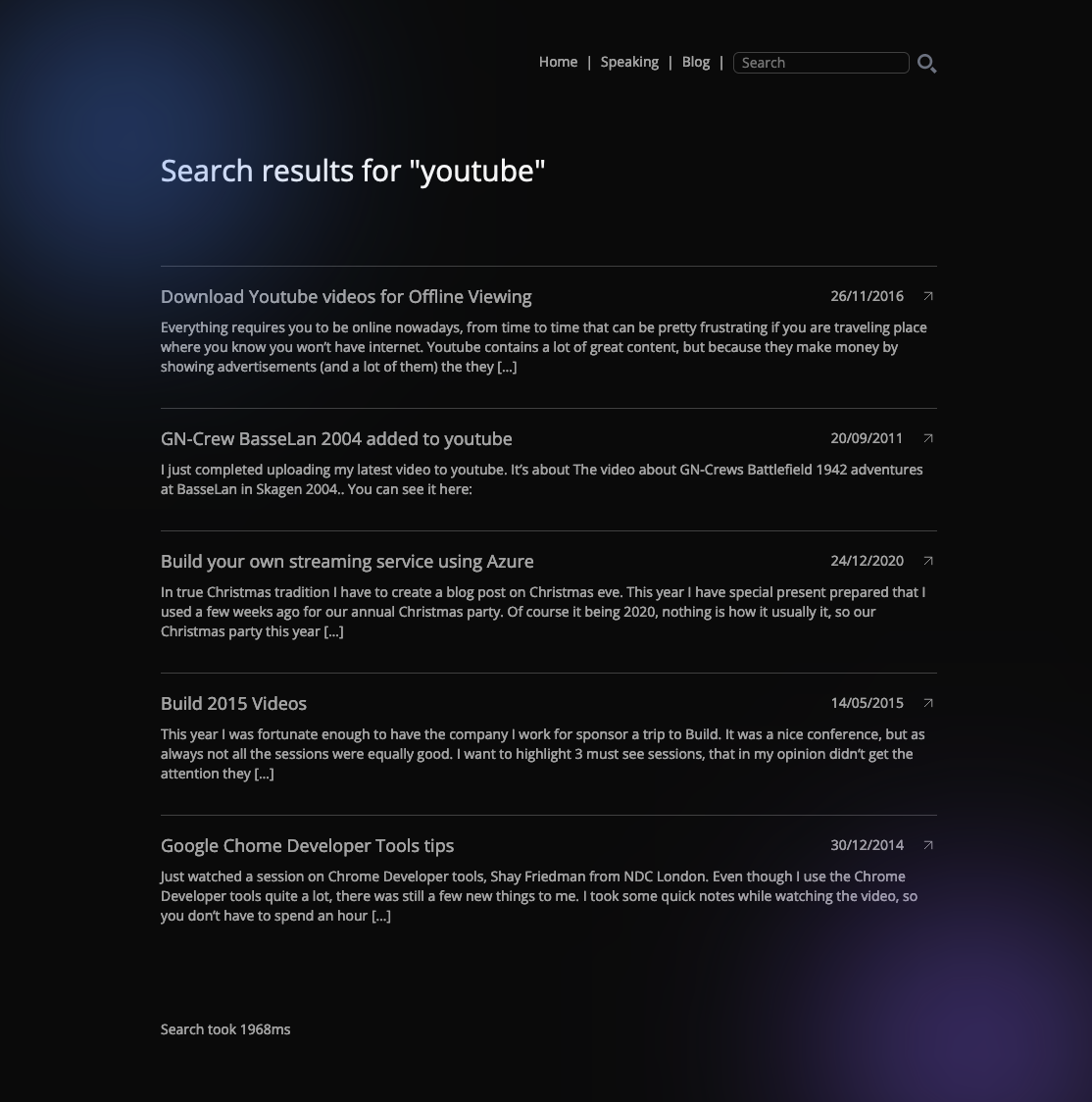
I decided to just do this in an Astro page, I know a lot of search systems actually use a modal, but I wanted to be able to link to the search results. Also this page will be the only dynamically generated page in my blog, all other pages are statically generated. I don’t have any server side rendering, so the dynamic nature of the page must be built in the browser.
The page source code looks like this
---
import { getCollection } from "astro:content";
import Layout from "@/layouts/Layout.astro";
import formatDate from "@/utils/formatDate";
const talks = (await getCollection("talks")).map((p) => ({
id: p.id,
slug: `/talks/${p.slug}`,
title: p.data.title,
publishedAt: formatDate(p.data.publishedAt!),
description: p.data.description,
}));
const posts = (await getCollection("posts"))
.concat()
.map((p) => ({
id: p.id,
slug: `/${p.slug}`,
title: p.data.title,
publishedAt: formatDate(p.data.publishedAt!),
description: p.data.description,
}));
const postmetadata = [...talks, ...posts];
---
<Layout title="Search results">
<main class="flex flex-col gap-20">
<article class="flex flex-col gap-8">
<h1 id="search-title" class="text-3xl text-neutral-100">
Search results
</h1>
</article>
<article id="search-result" class="flex flex-col gap-4">
Working on it...
</article>
<article id="search-timing">
</article>
</main>
</Layout>
<script src="./../components/SearchCard.ts"></script>
<script define:vars={{ postmetadata }}>
var inner = document.getElementById("search-result");
var timing = document.getElementById("search-timing");
let params = new URL(document.location).searchParams;
let searchQuery = params.get("q");
if (searchQuery == null || searchQuery == "") {
inner.innerHTML = "No results found.";
return;
}
document.getElementById(
"search-title"
).innerText = `Search results for "${searchQuery}"`;
fetch(`https://embedding.sjkp.dk?q=${searchQuery}`)
.then((response) => response.json())
.then((data) => {
timing.innerText = `Search took ${data.embedDuration + data.queryDuration}ms`;
console.log(data);
inner.innerHTML = "";
data.matches.matches.forEach((m) => {
postmetadata.forEach((p) => {
if (m.id.indexOf(p.id) > -1) {
var e = document.createElement("search-result-item");
e.setAttribute("post", JSON.stringify(p));
inner.appendChild(e);
}
});
});
});
</script>
I pass the metadata about all my posts to the JavaScript at compile/static page generation time. This makes the page content a bit large (34 KB, 100 KB uncompressed), but it was the only way to avoid using server side rendering. Obviously this wouldn’t be ideal if my page had a lot more content, in that case I would need to store the metadata in the vector database and let the API return it. Maybe a fix for when I don’t use Cloudflare.